说明
在 Flink 社区的努力下, Flink StreamSQL 和 BatchSQL 的语法可以做到基本一致,但在有些场景下, 两者还是有语义上的区别,因此有些情况下,不能按照离线处理的思维去写 StreamSQL,有可能会出问题。
Batch VS Stream
不一致 case
以下是目前在实际使用中常见的不一致的 case
乱序问题
在业务支持中, 最常见的就是乱序问题了, 在 Batch SQL 转化为 Stream SQL 时, 由于顺序的问题, 导致实时作业产生的结果和离线不一致。
Flink SQL 中 task 和 task 之间常见的传输方式就是 hash。 无论是 source -> group -> over window -> join -> sink
乱序场景的产生: hash-key 和下一计算阶段的主键不一一对应
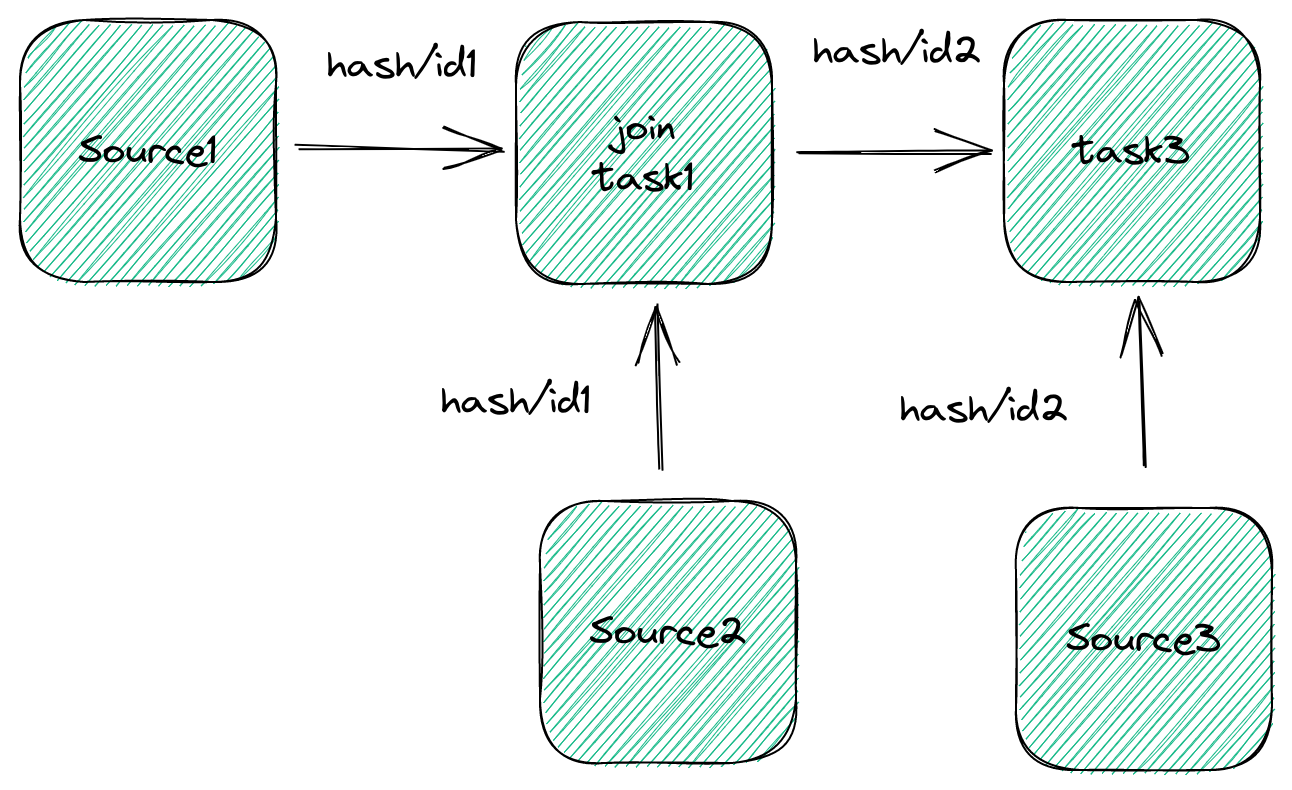
如上图所示: 实时表和另外两张维度表进行 join, join 的字段分别为 id1, id2
实际数据流向变化:
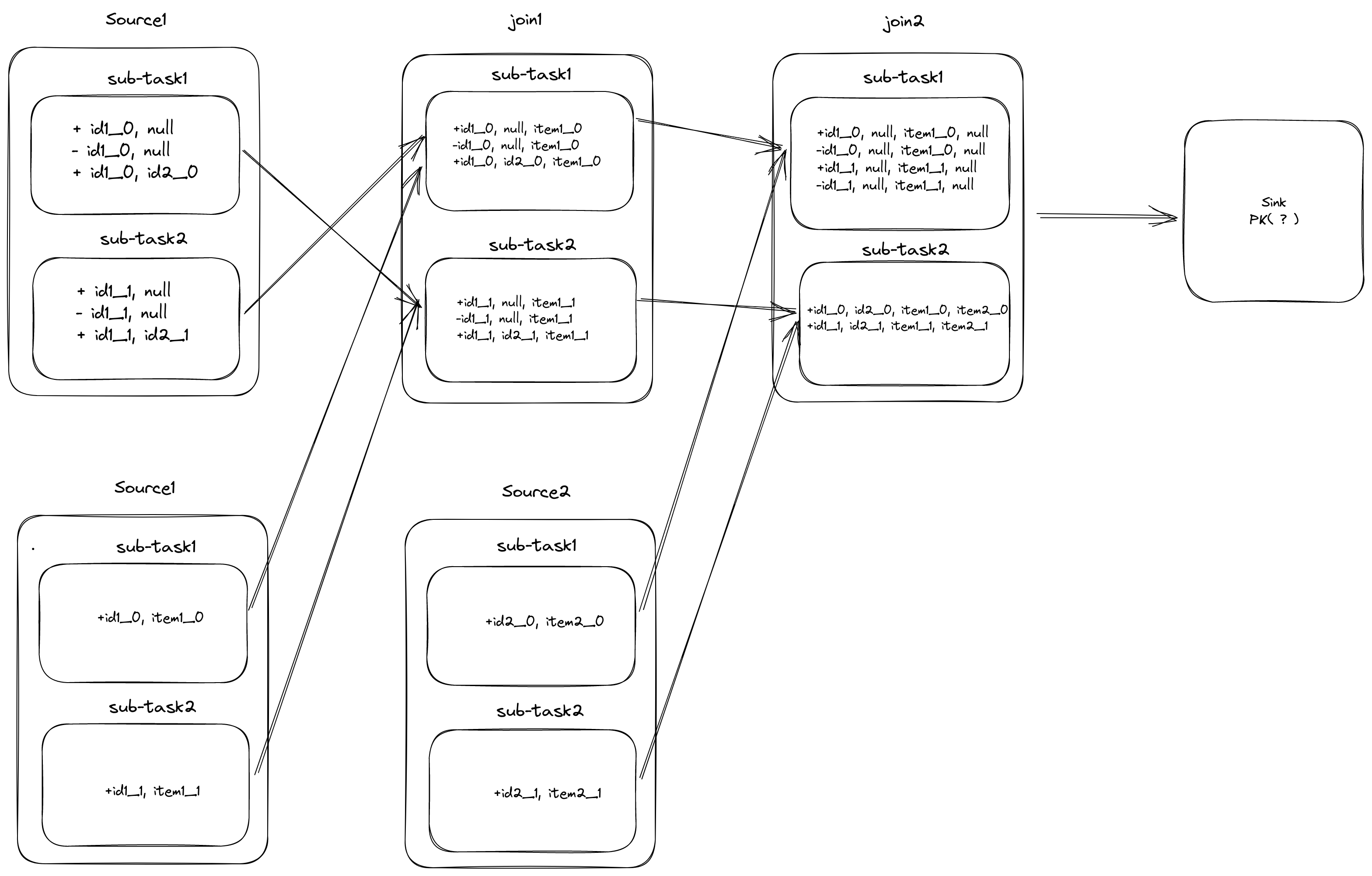
经过 join2, 数据按 id2 进行 hash,导致存在相同的 id1 数据会被 hash 到不同的节点,因此就无法保证 id1 的顺序性, 在 Sink 到外部系统时,大部分系统是直接基于主键进行更新,最终结果不符合预期
Retract 失效场景
Flink SQL 通过不断的更新和撤回机制,不断更新最后的计算结果,从而保证了和离线结果的一致性, 但是否存在某些场景 retract 并不能适用于所有场景呢?
当我们的计算中存在除法, 求幂等可能产生 Infinity value 时,就会破坏我们的计算结果。
以下面的 SUM 聚合为例子:
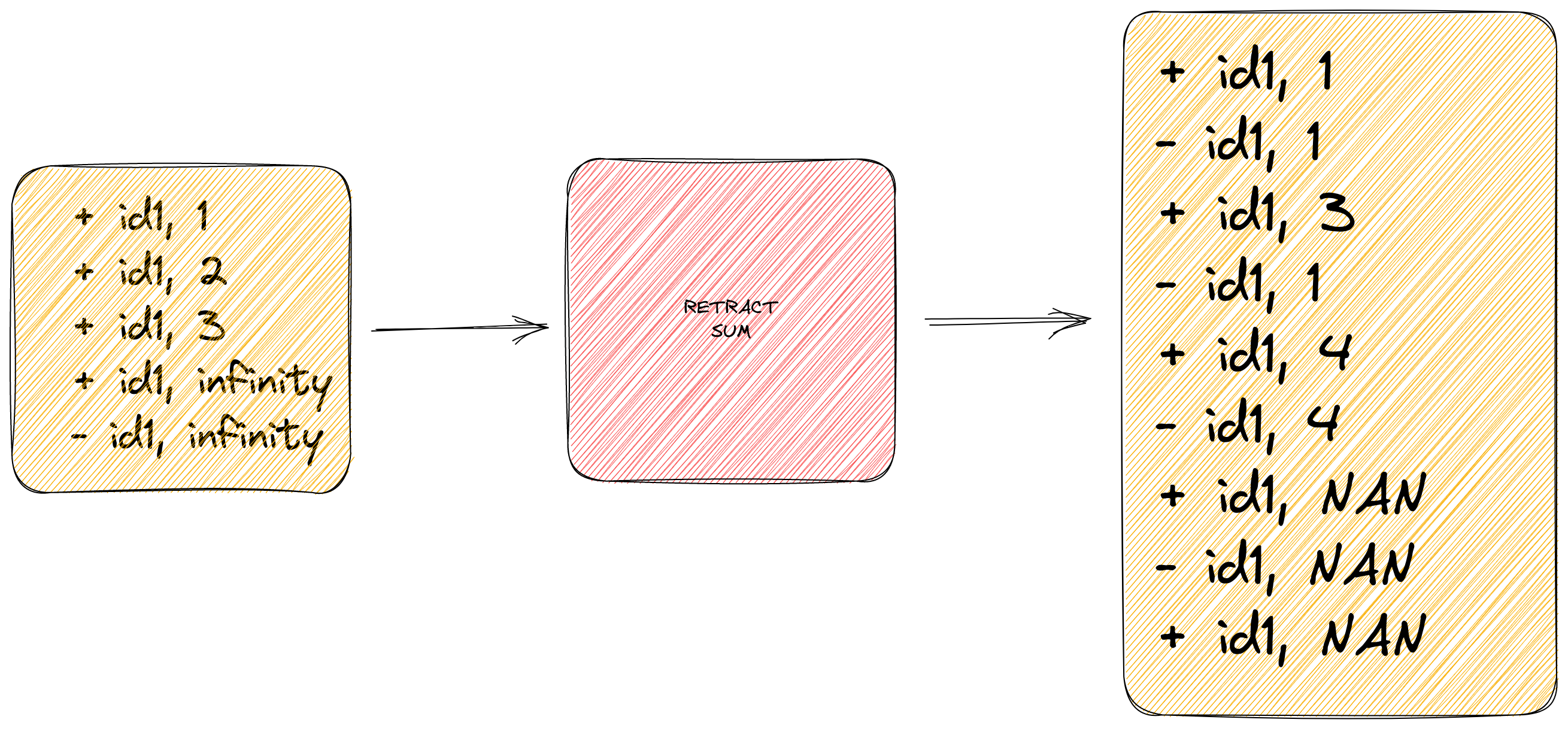
一旦聚合算子的输入存在 inifity 的值之后,我们的聚合结果一定会出现问题。
因此, 在聚合场景, 一定要确保聚合的字段一定不要产生 inifity 值。
以下面这段 SQL 为例子, Batch SQL 符合预期, 但实时 SQL 产生了 NAN 结果。
SELECT
key1,
key2,
key3,
case when min(value1) = 0 then 0
when min(value1) > 0 then power(10, sum(log(10, value1))))
FROM table1
GROUP BY key1, key2, key3
那实际生成的 DAG 图可能如下所示:

- 计算 log(10, value1) as log_val
- 计算 min(value1) as sum(log_val)
- 根据 min(value1) 的值来确定最终选择的结果
从逻辑来看, 只要确保了 min(value1) > 0 , 则可以确保 log 计算的值一定时合法的,但实时确并不是这样的, 关键在于针对 inifity value时, retract 机制并不能很好的 work
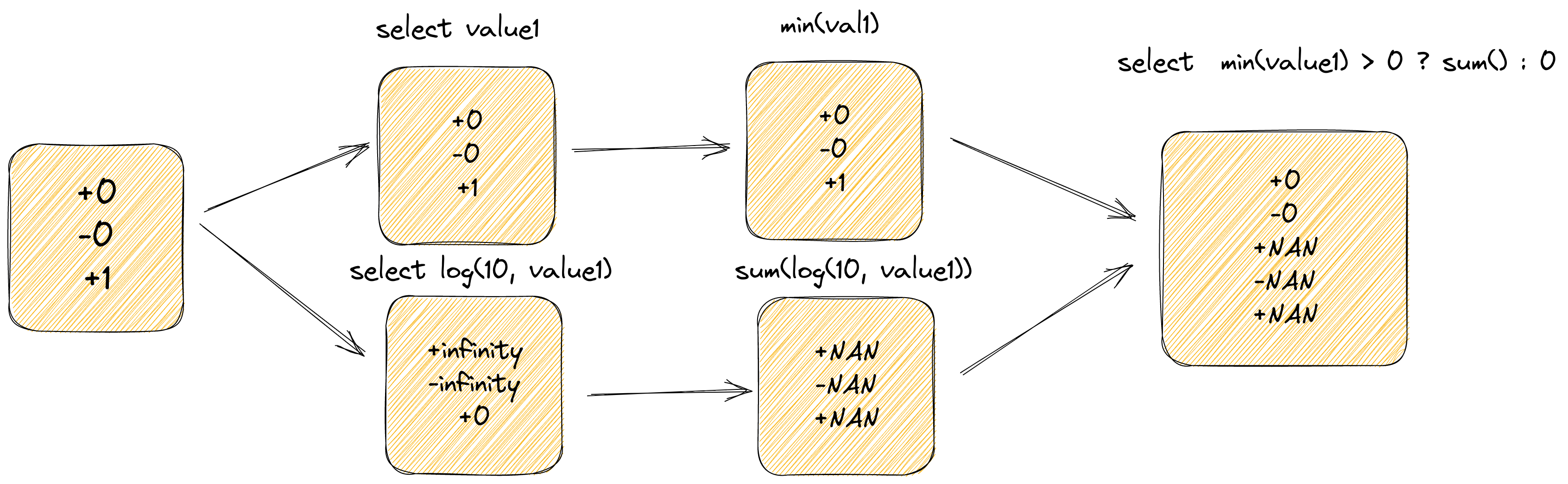
由上图可以看出, Flink SQL 并不能很好处理由 log(10, value1) 产生的 infinify value, 导致产生和离线不一样的结果。